0 引言
隨著微電子技術的迅速發展,嵌入式系統在一些特定的專用設備上得到了廣泛應用,通常這些設備的硬件資源(如處理器的運行速度、存儲器的容量等)非常有限,并且對成本也有苛刻的要求,有時對實時響應要求也比較高,在數字信號處理芯片上已經實現了語音口令識別系統或語音口令識別系統的部分功能。語音口令識別技術與嵌入式系統的有效結合能夠顯示出其優勢作用,但是也有很多有待進一步提高和改進之處,語音識別技術對運算速度和內存容量的要求都比較高,需要采用一些快速算法提高實時處理的性能。嵌入式微處理器的價格在不斷下降,但是其性能卻在不斷上升,嵌入式系統目前已經廣泛地應用于運算量比較大的系統和設備中,而其體積小和低功耗的特點使其能夠發揮出更大的優勢。
論文給出一種基于嵌入式系統的語音口令識別系統的設計方案,硬件系統的核心芯片是嵌入式微處理器,語音口令識別算法采用連續隱馬爾可夫模型,現有的非特定人語音口令識別系統中,多采用狀態輸出具有連續概率分布的連續隱馬爾可夫模型CDHMM(Continuous DensityHidden Markov Model)[3]。操作系統則是采用的目前廣泛使用的Windows CE 5.0。
硬件電路的核心芯片是三星公司的嵌入式微處理器S3C2440AL,主頻為400MHz。該微處理器具有低功耗、高性能等特點,廣泛應用于便攜式設備中。基于嵌入式系統的語音口令識別系統需要有接收語音信號的輸入芯片配合麥克風實現將模擬語音信號轉換成數字信號的功能,然后由嵌入式微處理器對輸入的語音口令信號進行處理。完成語音口令信號輸入功能的芯片采用的是PHILIPS公司的低功耗芯片UDA1341TS。操作系統采用的是Windows CE5.0。Windows CE 5.0是一個32位操作系統,具有模塊化、結構化,能夠支持超過1000個公共Microsoft Win32應用程序接口,并且與處理器無關等特點,為各種嵌入式系統和產品設計提供了一種可裁剪的、高效的、可升級的操作系統。
1 系統設計
1.1 硬件電路的設計
論文給出的語音口令識別系統的硬件電路主要由嵌入式微處理器、存儲器和語音口令輸入芯片組成。核心芯片是嵌入式微處理器Samsung 32位S3C2440AL,其主頻為400MHz,最高頻率533MHz。64MB SDRAM,64MB的NAND FLASH存儲器,用來存儲操作系統文件等,2MB的NOR FLASH存儲,為安裝BIOS使用。
S3C2440AL控制PHILIPS公司的UDA 1341TS完成輸入語音口令信號的功能。該音頻處理芯片由AD/DA轉換、控制邏輯電路、可編程增益放大器(PGA)和數字自動增益控制器(AGC)以及數字信號處理器等部分組成,能進行數字語音處理。
對于一個基于嵌入式系統的語音口令識別系統,主要有以下幾個要求:
(1)完成語音口令識別功能時,需要系統對人所發出的語音口令做出快速的響應,然后給出相應的判斷結果。
(2)自動獲得語音信號。語音口令識別系統一直處于隨時接受語音口令的工作狀態,無需人工操作就能將人的語音命令與環境噪聲分離出來,舍棄靜音信號和環境噪聲信號部分,僅僅對有效的語音口令信號做處理和識別。
(3)需要有足夠的存儲器容量存儲操作系統文件和訓練好的語音口令模型庫以及存儲大量數據的數據緩沖區。
論文給出的語音口令識別系統選擇高性價比的嵌入式微處理器S3C2440AL和64MB隨機存儲器和64MB的閃存來滿足計算速度和數據緩存的要求。
1.2 軟件程序的設計
選擇Windows CE 5.0為語音口令識別系統的操作系統,Windows CE 5.0是一個多任務操作系統。開發工具主要有Platform. Builder 5.0和EVC++4.0。Platform. Builder5.0用于定制和開發內核,而EVC++4.0則用來編寫基于操作系統的應用層程序,也就是算法執行程序與圖形化界面,而圖形化的界面使用MFC編寫。
由于語音口令識別系統算法的運算量比較大,所以為了能夠加快運算速度,首先對Windows CE 5.0操作系統進行配置,需要將相應的板級支持包BSP(Board SupportPackage)導入到Platform. Builder 5.0,裁剪掉一些使用不到的資源,保留一些需要的資源,驅動的配置正確后,將配置好的操作系統內核裝入到嵌入式平臺中,然后進行應用程序的開發。
語音口令識別系統分為訓練和識別兩個過程。訓練時,語音口令信號首先經過預處理,然后提取語音特征參數,采用MFCC(Mel-Frequency Ceptral Coefficients)參數[4],然后建立此口令的連續隱馬爾可夫(CDHMM)模型,把所有經過訓練的語音口令的模型放在模型庫中。
在識別階段,與訓練時提取語音口令信號的特征參數一樣,也要提取MFCC特征參數,然后與保存在語音口令模型庫中的每一條語音口令模型相匹配,根據概率*分確定輸出識別結果。語音口令識別系統的程序流程圖如圖1所示。
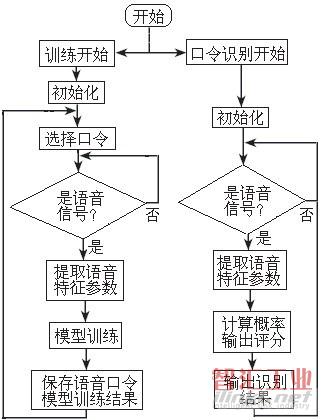
圖1 語音口令識別系統的程序流程圖。
當語音口令識別系統采集到命令語音信號后,要提取參數,做出比較判斷,調用相應語音口令識別算法。對每條語音口令信號,先切除靜音,進行預加重處理,然后通過Hamming窗分幀,幀長和幀移分別為20ms和10ms,對每一幀語音信號提取16階MFCC和△MFCC一共32維參數作為特征矢量。
語音口令識別軟件系統由許多不同的語音信號預處理、識別算法和其它子程序組成,為了實現參數的傳遞,每個程序執行后的參數以文件的形式輸出,而這些程序的調用先后順序和參數的輸入輸出文件的位置等都由一個主程序管理。
在Windows CE中,編寫可執行程序,需要調用應用程序編程接口API(Application Programming Interface)函數,并且要設定程序入口點。調用過程為:
無論是進行語音口令訓練還是語音口令識別操作,都需要對語音口令信號的采集和實時處理程序,所以對語音口令信號的采集和實時處理程序是語音口令識別系統軟件中的重要部分之一。對于語音音頻接口的管理是通過Windows CE 5.0里的API函數完成的,對語音口令信號的采集和實時處理程序流程圖如圖2所示。
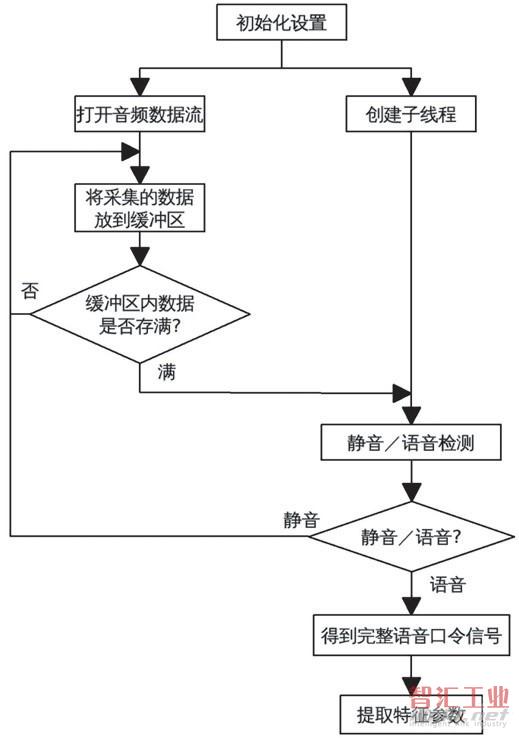
圖2 信號的采集和處理流程圖。
主程序在配置好初始化參數后,建立一個子線程,建立子線程有利于將靜音檢測的復雜運算過程和主程序的音頻數據采集過程分開進行,以確保在靜音檢測時不會丟掉音頻數據。與此同時,主程序開始采集數據,并存入到緩沖區。當預先設定好的緩沖區內的數據采集滿后,會將所采集的數據交給子線程,子線程做靜音檢測判斷。主程序會依然繼續重新采集新的音頻數據。對于子線程,子線程的任務是等待主程序發出命令,然后對數據做處理。如果檢測到有語音口令的開始,會繼續采集數據,得到完整命令語音口令信號,提取相應的特征參數。
具體程序中有如下幾個主要過程:
(1)初始化參數設置:
(a)FuncReturn=waveInOpen(&(Record_Buffer_Manager.hWaveIn),WAVE_MAPPER,&wFormat,(LONG)(RecordBufferFillProc),(DWORD)this,CALLBACK_FUNCTION);//首先要調用API函數打開音頻設備接口,并且設置相應的回調(CALLBACK)函數(回調函數是操作系統在每次緩沖區存滿后會自動訪問的一個特殊函數)
(b)Thread_process=AfxBeginThread((AFX_THREADPROC)RecordThreadProc,(LPVOID)this,THREAD_PRIORITY_NORMAL,0,0,0);//要為其單獨建立一個線程,為了實現靜音檢測,在混雜著環境噪聲的前提下,找出語音口令信號。
(c)FuncReturn=waveInStart(Record_Buffer_Manager.hWaveIn);//打開音頻數據流,開始錄音。(緩沖區存滿后,系統會自動訪問回調函數)
(2)主程序與子線程通信
SetEvent(pRecord-》hRecordEvent );//發出信號,使得子線程函數得到命令,對采集到的音頻流進行靜音的檢測判斷。
(3)在子線程內接收消息作出反應
WaitForSingleObject(pRecord-》hRecordEvent,INFINITE);ResetEvent(pRecord-》hRecordEvent);//與回調函數的信號發出程序對應,接受信號,并重新設定狀態,等待下一次信號。
……
pRecord-》ProcessData((SAMPLE_TYPE *)pRecord-》pLeftData,……);//將得到的數據段進行處理,也就是真正執行靜音檢測的部分。
(4)得到完整語音口令信號后提取特征參數。
2 結束語
論文建立了一種基于Windows CE的語音口令識別系統,并且對上升、下降等14條口令進行測試。實驗結果表明,本語音口令識別系統達到了實時的要求,可以廣泛應用于便攜式設備中。
(審核編輯: 智匯小新)
分享



